
Daily Update - May 1st, 2026
Intel EMIB yields, Qualcomm teases hyperscaler custom silicon design win, DeepSeek V4's SSD KV cache slashes inference cost

Competitors enter the fray. Intel’s EMIB is a legit alternative to CoWoS. Qualcomm throws it’s hat in the custom ASIC ring. But which ring? Not sure exactly what custom ASIC means here… And SSDs in DeepSeek V4 are seriously driving down inference cost. Let’s get into it.
Vik: I finished up at QCOM a week ago. Went on vacation this week. During the vacation, QCOM stock skyrocketed. Maybe I’m a market mover, but in the most embarrassing way. LOL.
Austin: I don’t know man…. maybe you should take more vacations!
Intel EMIB yield reportedly >90%
Intel’s EMIB advanced-packaging yields are reportedly above 90%, per GF Securities analyst Jeff Pu in a note out of MediaTek’s earnings.
Embedded Multi-die Interconnect Bridge (EMIB) is Intel’s advanced packaging alternative to TSMC’s CoWoS. It lets you interconnect multiple die at the silicon level rather than through an interposer.
EMIB ships in two flavors:
EMIB-T, with through-silicon vias (TSVs)
EMIB-M, with metal-insulator-metal (MIM) capacitors, useful for power connections through the EMIB die that need a bypass capacitor
Today EMIB scales to 8x reticle size. Intel’s roadmap targets 12x by 2028, matching what TSMC has guided for CoWoS. Google, NVIDIA, and Meta are all likely EMIB customers.

Austin: EMIB isn’t new by any means. For example, here’s a 2016 EMIB paper from Intel. It’s long been in production inside Intel server CPUs, GPUs, FPGAs.
So why the hype now? First, hyperscalers want a CoWoS alternative, and they want it yesterday. And EMIB-T and EMIB-M are genuinely useful. EMIB-T solves vertical power delivery necessary for EMIB to power HBM4, while EMIB-M improves local decoupling and signal integrity for UCIe-A-class high-speed die-to-die interfaces.
Also, Vik, not sure if you saw it on vacation, but $INTC went to the moon 🚀
Qualcomm hinted they’re in the custom ASIC game
In yesterday’s daily update, we covered Qualcomm’s auto strength.
The other earnings call moment worth flagging was the tease of custom silicon. CEO Cristiano Amon said, “We're also entering the custom silicon space, beginning our ramp with a leading hyperscaler, and we expect initial shipments in the December quarter”.
What form that design win takes is anyone’s guess. Amon kept fairly mum, other than to say more to come at the Qualcomm Investor Day on June 24, 2026.
Vik: AI200/250 got a similar stock pop with limited detail attached. I’d want to see more substance before drawing conclusions.
Austin: Qualcomm CEO Cristiano Amon is giving a Computex Keynote on June 1. Between that and the investor day on June 24, I expect we’ll learn a lot more about Qualcomm’s datacenter and custom ASIC aspirations.
Deepseek V4: KV cache compression and cost
Quote from FundaAI (from free part of post):
DeepSeek’s accumulated engineering work on SSD-based KV cache, which together migrate KV cache from expensive, capacity-limited DRAM / HBM onto larger and cheaper SSD at scale. We believe DeepSeek V4’s cache-hit repricing implies upside for SSD, with NAND demand set to grow exponentially.
This is the importance of context storage systems in inference. It is always better to store large amounts of KV matrices in SSDs and achieve a massive reduction in cost due to a high cache hit rate. DRAM does not provide that kind of capacity/cost ratio. Vik covered this extensively in his deep dive on context storage. Now we are seeing it play out in action in Deepseek v4 with 95%+ cache hit rates.
From the original post in Jan 2026:
In short, context storage systems when deployed fully will drive down the cost of inference significantly, especially for long context cases.
DeepSeek V4 is proof. Cost of tokens with cache hits have now fallen dramatically.
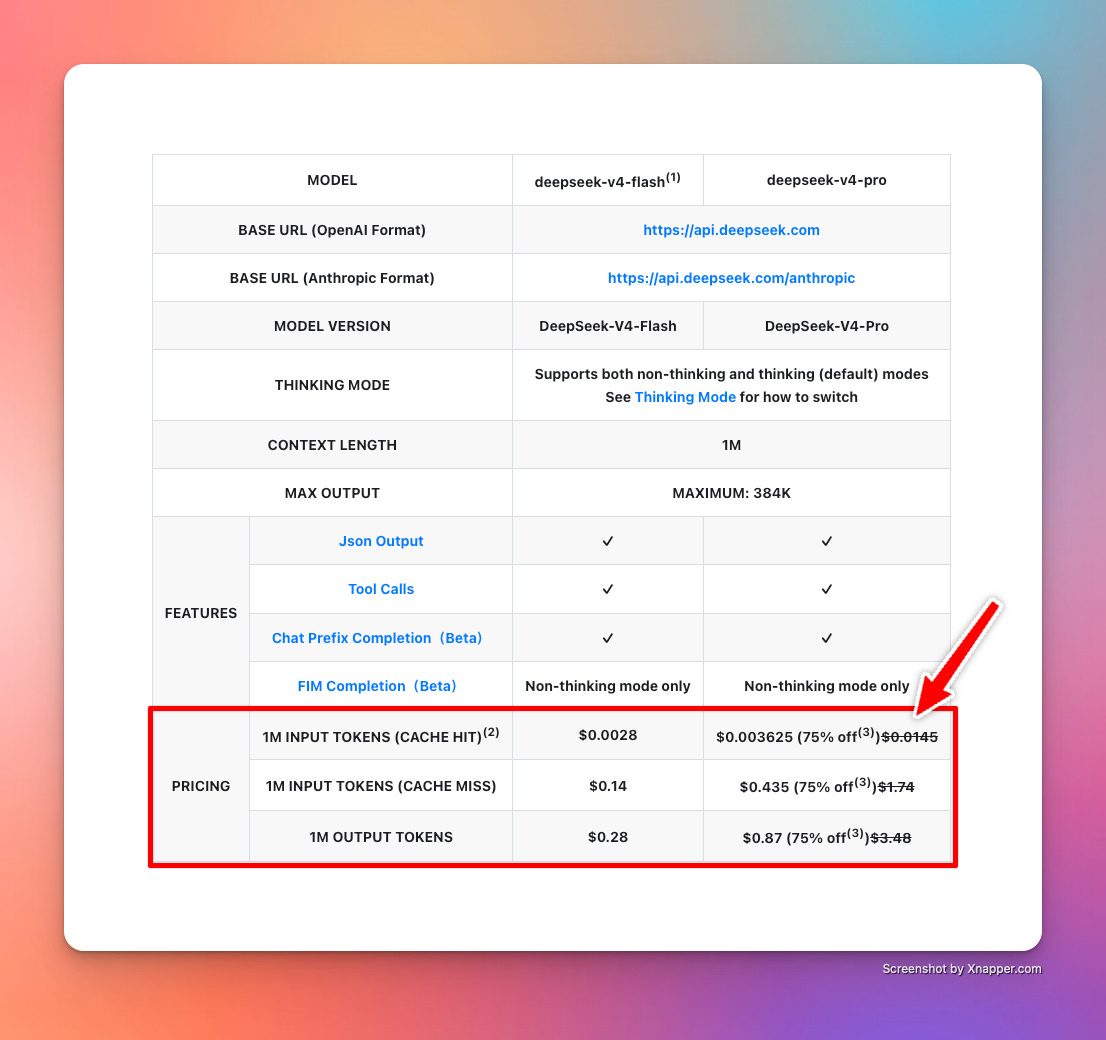
Austin: Vik, dude, you could have taken more of a victory lap on this one. Regardless, great topic, we should keep digging into SSDs and the impact on tokenomics.
That’s it for today!